
Face Choir is a prototype system for networked collective interaction that allows spatially distributed participants to generate vowel sounds using their facial movements, simulating a collective choir singing experience while being apart.
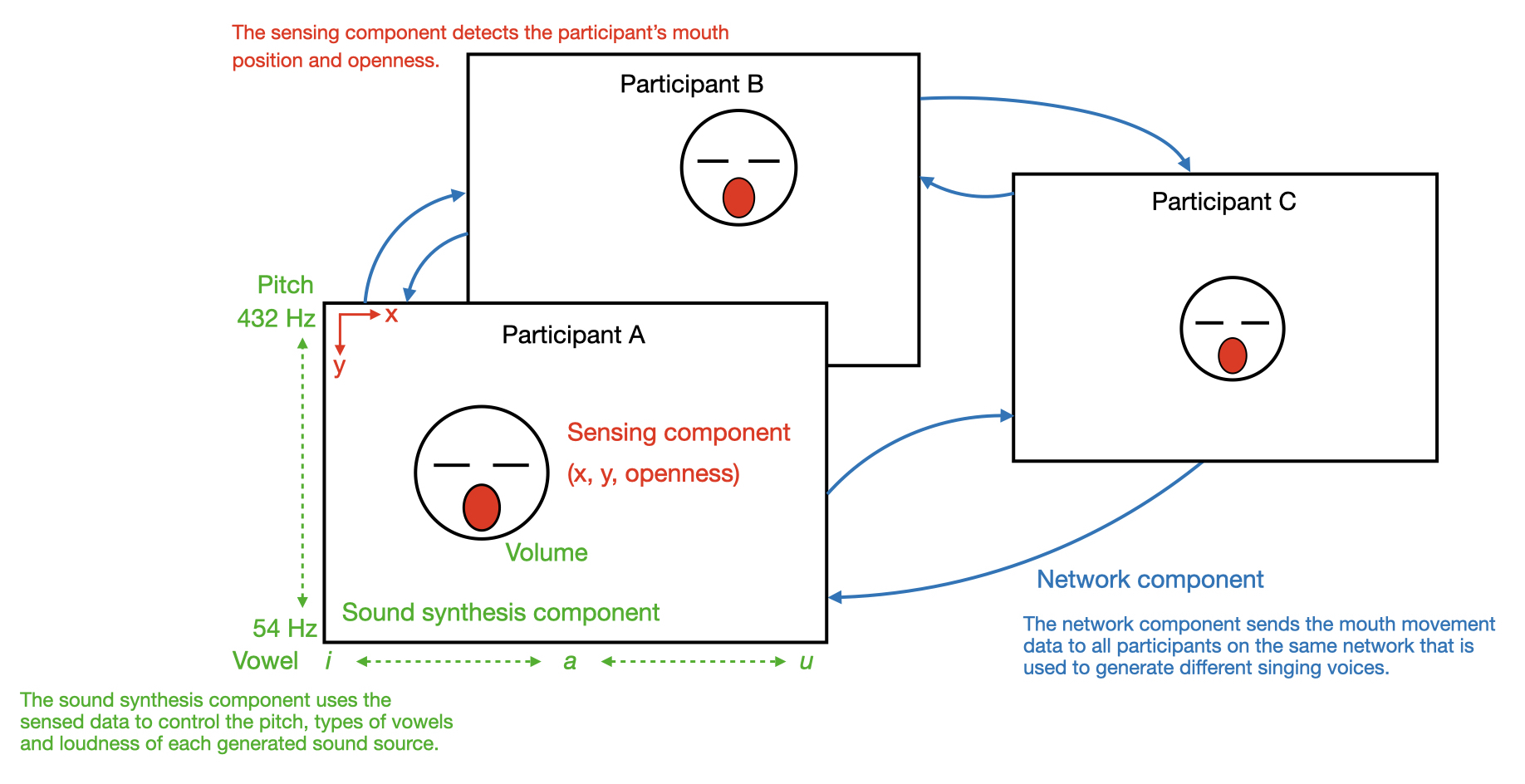
Participants can join the performance by entering a webpage with access to their cameras. On this page, the live camera image is displayed and a face-recognition system is at work. Once the recognition system detects the face of the participant, it tracks their mouth movement and uses this information to control a vowel sound synthesizer. The position of the mouth (x, y) changes the pitch (the higher up on the y-axis the higher the pitch) and the quality of the vowel sound (from 'ee' to 'a' to 'o' as the mouth move from left to the middle to right). The openness of the mouth changes the volume of the sound (the bigger the mouth opens the loud the sound gets). Meanwhile, the mouth data are send to all the other participants joining at the same time, allowing everyone to perform, or sing, in harmony across the distance.
The participant only sees their own video image with a circle providing visual feedback about their mouth movements, the presence of other participants are only perceived via sounds.
Try it out below:
Face Choir is largely inspired by the exercises and technologies during the Experiments in Networked Performance course from School for Poetic Computation (taught by Tiri Kananuruk & Todd Anderson).